

ChatGPTとの昔のチャット内容を「そういえば、あれどこかに書いてあったよね?」と、過去に遡って探すことってよくありませんか?
ひとつひとつのチャット内容は大した文字数でなくても、積み重なると結構なデータ量になったりします。
また、先日も起きましたが、OpenAI側の不具合でチャット内容の閲覧ができなくなったりする事態に備えて、自分のPCで管理できると安心です。
今回、エクスポートしたチャット内容のJSONファイルからタイトル別に日付を付与してMDファイルに自動変換するスクリプトを作ったのでご紹介します。
データ作成手順
過去のチャット内容エクスポート
1.左下のアカウントをクリック→設定→データコントロール→チャットをエクスポートする
2.確認後、エクスポートが実行されます。
3.登録メールアドレスにエクスポート完了のメール”ChatGPT – データ エクスポートの準備ができました”が届くので、そのメールからダウンロードを行います。
4.エクスポートしたZIPファイルを解凍します。
解凍時のエラーについて(Windowsの場合)
エクスポートしたZIPを展開するときに「ファイル名が長すぎる」というエラーが出るのは、Windows環境でよくある現象です。
原因
Windowsはデフォルトで パス(フォルダ名+ファイル名)の長さを260文字まで に制限しています。
ChatGPTのエクスポートJSONの中には「めちゃくちゃ長いタイトルやハッシュ値」がファイル名として保存されることがあり、これが制限を超えてしまうためにエラーとなります。
対処法
方法1:展開場所を浅い階層にする
- 例えば
C:\chatgpt\直下にZIPを置いて展開すると、パスが短くなるので解決することがあります。
(C:\Users\〇〇\Documents\Downloads\chatgpt-export\...みたいな長い場所だとアウト)
方法2:Windowsの「長いパスを許可」を有効化
- Windowsキー + R →
gpedit.mscを開く。 - [ローカルコンピュータポリシー] → [コンピュータの構成] → [管理用テンプレート] → [システム] → [ファイルシステム] を開く。
- 「Win32の長いパスを有効にする」を 有効 にする。
- 再起動後、最大 32,767文字までOK。
(※ Homeエディションだとグループポリシーエディタがない場合があります。その場合はレジストリで設定可能です)
方法3:7-Zipなどの別の解凍ソフトを使う
標準のエクスプローラーでは失敗しても、7-Zipなら展開できるケースがあります。
ちなみに私は、方法1+方法3で解凍できました。
Pythonで自動生成
対象ファイル
解凍したファイル内は以下のような構成になっています。
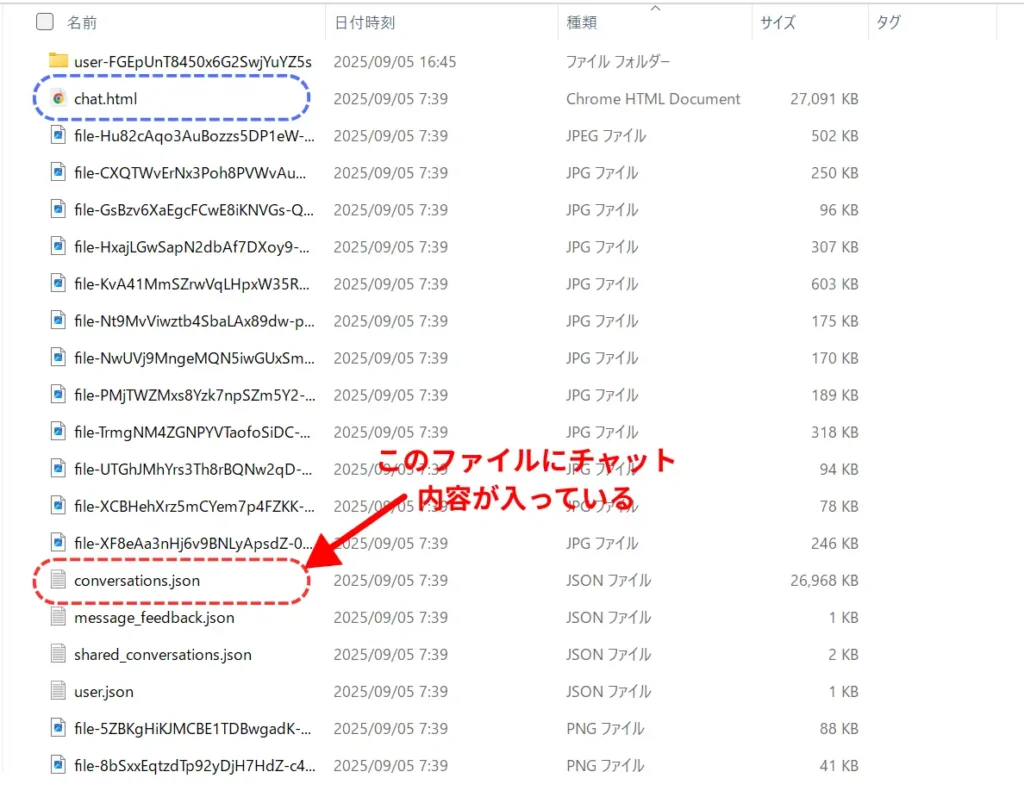
- conversations.jsonが対象ファイルです。このファイルを読み込んで、チャットの日付をタイトルの頭につけた名前でMDファイルを作成します。
- 青枠で囲ったchat.htmlファイルは手軽で見やすく内容を確認できますが、すべてのチャットがずっと下に続く形なので、件数が多い場合は探すのが大変ですよね。また、チャットの日付は表示されません。
- チャット内の画像や表などもすべてエクスポートされています。やたら長い名前がついていますね。これが解凍時のエラー要因になりがち。
Pythonスクリプトを実行する
import os
import json
import re
from datetime import datetime
# JSONファイルのパス
json_path = r"(ここにJSONファイルのパスを記入)\conversations.json"
# Markdownファイルの保存先フォルダ
output_folder = r"(ここに保存先フォルダのパスを記入)\(保存先フォルダ名)"
os.makedirs(output_folder, exist_ok=True)
# Windows禁止文字を置換する関数
def sanitize_filename(title):
return re.sub(r'[\\/:*?"<>|]', '_', title)
# UNIXタイムスタンプをYYMMDDに変換
def format_date(ts):
if ts is None:
return "unknown_date"
try:
return datetime.utcfromtimestamp(ts).strftime("%y%m%d")
except Exception:
return "unknown_date"
# 再帰的にノードからメッセージを抽出
def extract_messages(mapping, node_id):
node = mapping.get(node_id, {})
msgs = []
message = node.get("message")
if message and message.get("content"):
parts = message["content"].get("parts", [])
# dict が混ざっていても文字列化
clean_parts = []
for p in parts:
if isinstance(p, str):
clean_parts.append(p)
elif isinstance(p, dict):
clean_parts.append(p.get("text", str(p)))
else:
clean_parts.append(str(p))
text = "\n".join(clean_parts).strip()
if text:
role = message.get("author", {}).get("role", "unknown")
msgs.append(f"**{role}**:\n{text}\n")
# 子ノードも再帰処理
for child_id in node.get("children", []):
msgs.extend(extract_messages(mapping, child_id))
return msgs
# JSON読み込み
with open(json_path, "r", encoding="utf-8") as f:
data = json.load(f)
count = 0
for conv in data:
title_raw = conv.get("title", "no_title")
title = sanitize_filename(title_raw)
create_ts = conv.get("create_time")
date_str = format_date(create_ts)
# ファイル名は「日付_タイトル.md」
filename = f"{date_str}_{title}.md"
filepath = os.path.join(output_folder, filename)
# 会話本文を抽出
mapping = conv.get("mapping", {})
root_id = "client-created-root"
if root_id not in mapping:
continue
messages = []
for child_id in mapping[root_id].get("children", []):
messages.extend(extract_messages(mapping, child_id))
# Markdownに書き込み
with open(filepath, "w", encoding="utf-8") as f:
f.write("\n".join(messages))
count += 1
print(f"Saved: {filepath}")
print(f"{count}個のMarkdownファイルを作成しました。")
上記スクリプトを実行すると、チャットの数のMDファイルが作成されます。
Obsidianでノートを作る
Obsidianはマークダウンエディタなので、新しいVaultを作成して上記のMDファイルをまとめて放り込めばそのままノートとして管理されます。
リンクを貼ればダウンロードされた画像や表もノート内で見ることができるので便利。
工夫次第でいろいろな使い方ができますね。

まとめ
私は今まで、チャットのタイトルにrenameで日付を頭につけていたのですが、JSONファイルの中に作成日付(時間も)があるのがわかり、これをタイトルに自動で付けられたことがメリットでした。やっぱり時系列で見たいことって多いですよね。
良ければ、試してみてください。お役に立てれば嬉しいです。
本記事のスクリプトは Python 3.13 (64bit) / Windows 11で動作確認しています。
標準ライブラリのみを利用しており、追加のインストールは不要です。
ご自由にコピー・改変してお使いいただけますが、動作の保証はできません。
利用により生じたいかなる損害についても、当方は責任を負いませんのでご了承ください。

